What are the Best Data Aggregation Methods for Oracles in Volatile Web3 Markets?


A key element in web3? Providing accurate and real-time data from multiple sources on-chain, which is vital for smart contracts to interact in a reliable and timely manner. Oracles are the integral devices or entities that ensure the integrity and stability of decentralized finance (DeFi) ecosystems by serving as intermediaries that bridge the gap between off-chain and on-chain data sources.
Oracles continue to advance, with debate raging about the best and most efficient method of data aggregation for oracles. Let’s explore two simple types—those using the “mean” and “median” methods—plus examine a few possibly superior solutions. Get your head around how data aggregation for oracles impacts liquid staking and restaking tokens in volatile markets.
Industry-leading Chainlink first to solve the oracle problem
Oracles were first conceptualized and developed between 2012 and 2015, growing in importance as Ethereum gained traction. They ensure blockchains can connect to existing legacy systems, data sources, and advanced calculations in a reliable and timely manner. This is integral to the functioning of smart contracts, which are inherently isolated and deterministic, and are unable to access or retrieve data from external environments without an intermediary.
Chainlink is the industry-standard oracle in web3, already enabling trillions of dollars in transaction volumes and creating an extensive ecosystem that caters to some of the largest names in the industry. Chainlink is blockchain agnostic, meaning that it connects all major public and private blockchain environments using a single framework. This same framework provides a typical abstraction level for cross-network communication.
The “oracle problem”—the inability of blockchains to access external data, making them isolated networks—is solved by Chainlink which uses a decentralized network of entities to:
- Retrieve data from multiple sources
- Aggregate it, and
- Deliver a validated, single data point to a smart contract to trigger its execution.
Mean vs. median data aggregation methods
Data aggregation is the process of collecting different values, usually from different sources, and summarizing them into a single value. Aggregating these values increases the correctness of the data. Aggregating price values is integral in web3 as it is foundational to developing applications for synthetic and derivative assets, insurance, lending, and many other uses.
Let's look at the two basic methods of data aggregation—using the mean and median—and the benefits and challenges of each.
The first data aggregation method uses the mean value. This very simple method averages data from multiple sources. As an example, assume that you want the most correct price of ETH/USD from three different exchanges. An oracle would take the price from each exchange and then calculate the average price to consolidate the data into a single value.
This is a simple and fair method to aggregate data, as it reflects the overall trend of the data and is suitable for stable and consistent market conditions. The downfalls are that the method is susceptible to extreme values and outliers, has the potential for skewed results in volatile markets, and is less robust against market manipulation or errors in individual data points.
As an example, imagine that you are calculating the mean value from three different exchanges for the price of ETH/USD. The prices are $2000, $2000, and $1100 on exchanges 1 through 3, respectively. The average price would be $1700, but that is not an accurate representation of the “real” price of Ether.
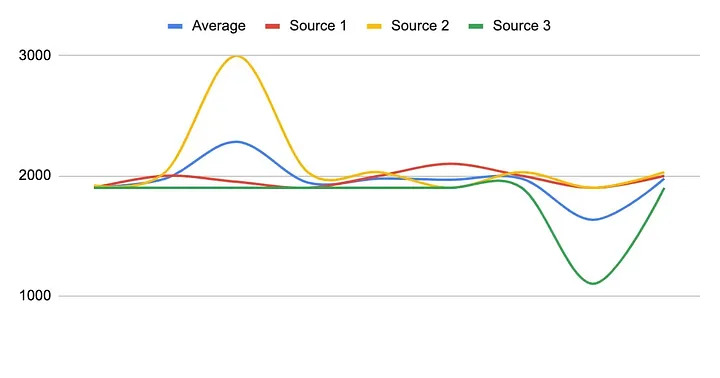
The second data aggregation method uses the median value. This is another simple method that involves finding the “middle” value from multiple sources. Using the median is advantageous as it’s more resistant to outliers and extreme values, provides a more accurate representation in volatile markets, and reduces the impact of data manipulation and errors. Calculating the median is also more complex compared to the mean, may not reflect the overall trend if the data distribution is uneven, and can have a delayed response in rapidly changing markets.
Continuing the previous example, imagine that you are finding the median value on three different exchanges for the price of ETH/USD—but this time one exchange has a trading volume of $100 million while the others are under $10K. If the price on the larger exchange is $2000 and the others are at $1500, then the median value would be $1500 and not reflective of the “real” market value of Ether.
Concentrated liquidity in LSTs & LRTs tricky to aggregate
One of web3s early pitfalls, which some see as a feature, is adverse market conditions. Early-stage markets with low amounts of liquidity, compared to traditional financial markets with trillions, can experience sudden price crashes and extreme volatility. Two crypto asset types that may be acutely susceptible to changing market conditions are liquid staking and restaking tokens.
Liquid staking tokens (LSTs), like stETH from Lido, enable users to stake Ethereum and earn staking rewards while retaining liquidity. Liquid restaking tokens (LRTs) take this concept a step further by enabling users to stake their LSTs to earn additional rewards. Staking on the Ethereum network has grown rapidly, with 31 million ETH (26% of supply and ~$120 billion in value) staked on the Ethereum Beacon chain.
The LST market is highly concentrated, with 9.8 million ETH staked through Lido alone and Lido holding 31% market share. This creates problems of centralization, and also makes it difficult for oracles to relay accurate and reliable price data when using mean or median data aggregation methods. As there are only a few—or sometimes only one—data sources, the usability of the data is brought closer to a single point of failure. LSTs and LRTs are exposed to these methods' weaknesses during adverse market conditions.
De-pegging, liquidity risk & concentrated sources inhibit LST and LRT markets
There are two main risks to consider for LSTs during adverse market conditions:
The first is price dislocations, also known as a de-pegging, between LSTs and their underlying assets. De-pegging creates arbitrage opportunities across different markets, and although arbitrage helps mitigate price discrepancies during normal market conditions, it can amplify risk during significant market events.
A well-known example is when the price of stETH deviated from its peg during the Terra Luna collapse in early 2022. The asset traded at $0.935 (-6.5%) on Curve Finance and triggered cascading liquidations for entities, such as Three Arrows Capital, leveraged on stETH.
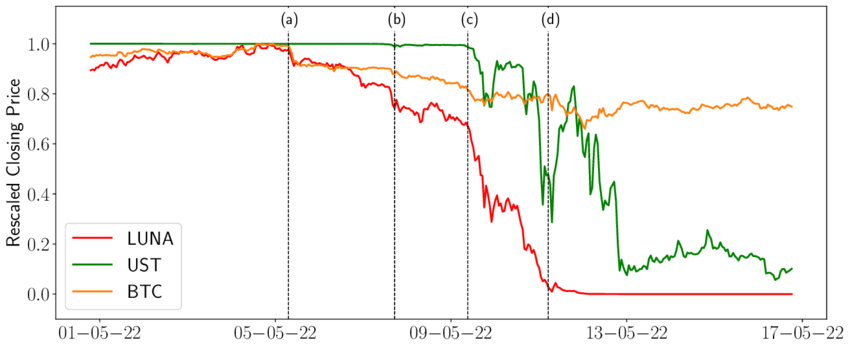
The second is liquidity risk. Liquidity on secondary markets, including centralized exchanges (CEXs) and decentralized exchanges (DEXs), is crucial for enabling users to enter and exit staked positions without significant slippage. By concentrating liquidity in few sources, such as the stETH/ETH pool on Curve, leveraged LST holders risk substantial losses. Ensuring a broad liquidity distribution on- and off-chain is key for ensuring safety.
LRTs introduce challenges similar to those associated with LSTs—such as the concentration of assets in restaking protocols, liquidity shortages in secondary markets, and the limited integration of LRTs across on-chain ecosystems. LRT platforms can minimize these risks by prioritizing sustainable liquidity sources and considering the yield denomination, duration, and redemption rates of the assets.
Combining data aggregation methods & Optimistic oracles for possible solutions
DeFi moves fast, with its accessible, distributed, and engaged nature driving innovations. What are some solutions emerging to ensure that oracles function effectively during adverse market conditions?
The first is using a combination of data aggregation methods. Instead of using just one simple method, such as the mean or median, using combination methods such as Volume-Weighted Aggregated Price (VWAP) or Time-Weighted Average Price (TWAP) can reduce risk during volatile market conditions.
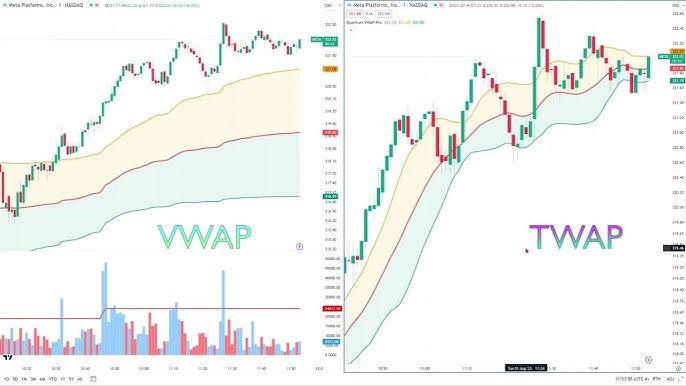
VWAP is a trade-based price determination that takes into account the different volumes of trades from different sources. The more trading volume a source has—the larger the weight of its price value. TWAP is a weighted-average price defined by a time criterion. Using TWAPs is useful for calculating price values in limited-liquidity markets such as those found on DEXs, plus make market manipulation harder when data sources are limited.
Optimistic oracles are another effective solution. These types of oracles consist of pseudonymous actors that relay truths on-chain, driven by economic interest. These truths expand on single-value data, which may be price feed oracles, to all arbitrary data. They work by a requester requesting an answer, a proposer providing an answer, and then a disputer challenging the answer (if necessary).
Optimistic oracles are effective, but present a challenge because the results may not be instantaneous—something that users aren’t attuned to in the fast pace of DeFi. While price feed data is already a common output of existing oracle solutions, in the future there will be an increasing need for truthful answers for use cases that extend beyond price data.
Oracles & data aggregation methods continue evolving
The integration of oracles in web3 has been instrumental in bridging the gap between deterministic blockchains and the dynamic real-world data necessary for smart contract functionality. As oracles evolve, the debate over the best and most efficient data aggregation methods becomes increasingly important, especially in the context of volatile and rapidly growing markets.
LSt and LRT markets face heightened risks during adverse conditions, including de-pegging and liquidity risks. Innovative approaches like combining VWAP and TWAP methods, and the development of Optimistic oracles, offer some promising and exciting solutions.



